・pandasを使ってcsvを編集したい方
・pandasのデータ範囲を指定した削除方法を調べている方
など
理系の社会人の方や学生の方は
仕事や研究で、データを取り扱っているとcsvファイルの整理をすることも多々あるかと思います。
ただ、市販の何かしらのソフトウェアを使っていたりすると
実際に自分は使わないデータを含んでる事もよくあるんじゃないでしょうか。
今回はPythonライブラリのpandasを使って、
削除するデータ範囲を指定して、csvファイルを保存するコードを紹介します。
今回のお題
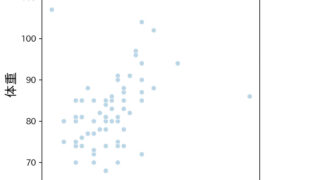
origin.csvというファイルを用意して、中のデータは以下の写真のようにしました。

このcsvファイルから
・11~15と21~25の数字が書いてある行
・ヘッダー(1番上の行)がb~cの列
を削除するコードを書いていきます。
コード
origin.csvと同じディレクトリ(フォルダ)に以下のmain.pyを置く想定で書いたコードがこちら
import pandas as pd
#行範囲で削除する関数
def delete_rows(csvname:str, new_csvname:str, init:int, last:int):
df = pd.read_csv(csvname)
row_deleted = df.drop(range(init, last), axis="rows")
row_deleted.to_csv(new_csvname, index=False)
#列範囲で削除する関数
def delete_cols(csvname:str, new_csvname:str, init:int, last:int):
df = pd.read_csv(csvname)
col_deleted = df.drop(df.columns[init:last], axis="columns")
print(col_deleted)
col_deleted.to_csv(new_csvname, index=False)
def main():
delete_rows("origin.csv", "rows_delete.csv", 1, 3)
delete_cols("origin.csv", "cols_delete.csv", 1, 3)
if __name__ == "__main__":
main()
少し汎用性を出すために、入出力のファイル名2つと範囲の最初と終わり表す整数2つを引数にもつ
関数として表現しました。
以下ポイントを少しだけ解説。
csvの読み込み
いつも使っているread_csvメソッドを使用しました。
行・列の範囲指定削除
read_csvで読み込んだDataframeに対して、dropメソッドを使用しました。
行の範囲削除では
drop(range(削除したい最初の行, 削除したい最後の行+1), axis=”rows“)
列の範囲削除では
df.drop(df.columns[削除したい最初の行:削除したい最後の行+1], axis=”columns”)
と記述します。
Pythonではよくpandasに限らず、範囲指定の際に最後の数字は+1するのが慣例になってますね。
おわりに
ここまで読んでいただき、ありがとうございました。
実は学生時代は、あまりpandasを使っていなくて
ずっとnumpyばかり使っていたので、最近はimpressの教科書で再度勉強してます。
DataFrameというpnadas独特な仕組みの説明から、取得したデータを使ってグラフ描いたり機械学習するまでコード付きの解説もあったので、お勧めしてます。
最近は大雨がすごかったですね。
もうすぐ夏ですので、急な雷やゲリラ豪雨なども発生しやすくなっていると思いますが
自身の安全第一な行動を心掛けください。
それでは。