・Pythonを使って Excelデータの読み込ませる方法を知りたい方
・pandasのデータフレームから特定の行を抽出したい方
どうもこんにちは。
コンです。
私が所属している製造業みたいな分野では Excelが主流で使われていて
まるで Excelが文章を書くツールかのように使われている場面すらあります。
ブログでも頻繁に ExcelとPythonを組み合わせたものを紹介しているのですが
今回は Excelのデータで条件が一致したデータを抽出したいと思います。
今回のお題
千葉商科大学さん(https://www.cuc.ac.jp/)の提供してくださっているプロ野球選手のポジション・身長・体重のデータを今回も使いたいと思います。
データはもちろん?日本のプロ野球球団の全12球団の選手データが入っておりあます。
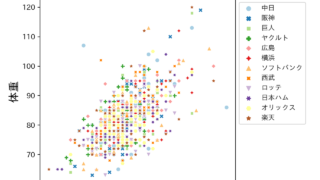
以前はこのデータを使って身長と体重のデータを可視化した散布図について解説したのですが
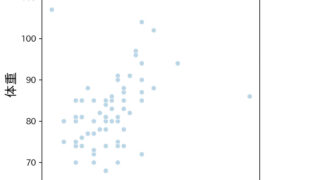
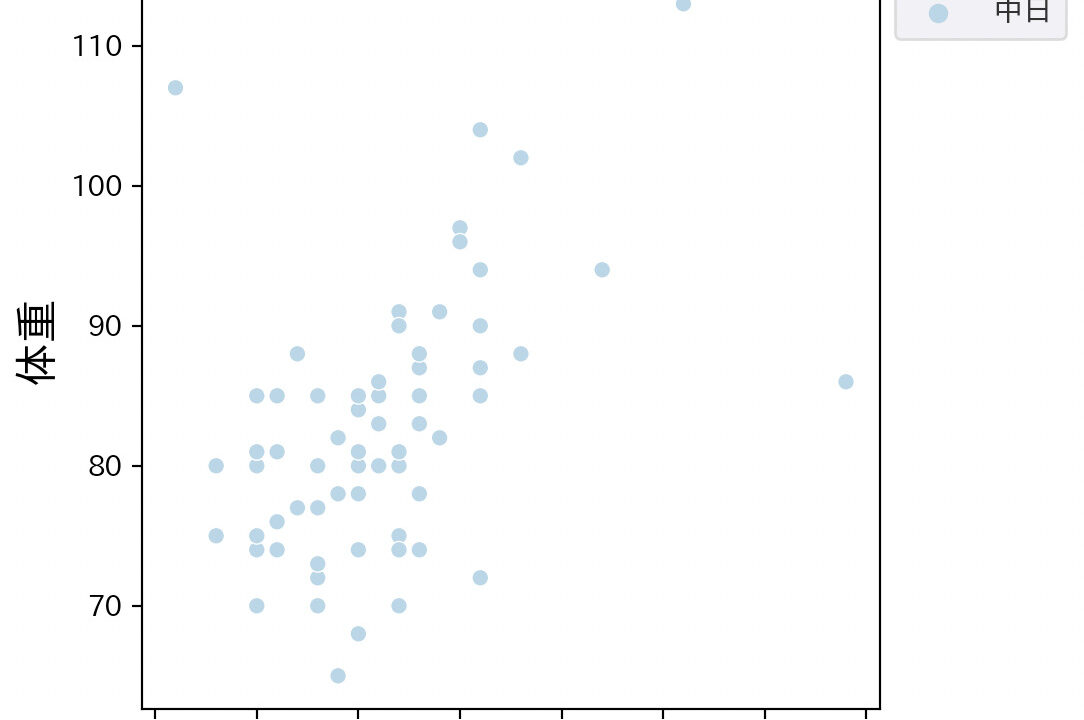
今回はデータ中から「中日」に所属している選手のデータだけを抽出してみます。
コード
pandasを使ってExcelを読み込んだ後に、中日のデータを抜き出すコードを下に示します。
コピペして使ってもらっえれば幸いです。
(作図の部分はお好みでどうぞ)
import pandas as pd
#Excelを読み込んで散布図を書く
df = pd.read_excel('baseball.xlsx')
#データ抽出
ch_df = df[df['球団'] == '中日']
height_box=ch_df['身長']
weight_box=ch_df['体重']
team_box=ch_df['球団']
##########ここから図を書くコード##########
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
#x:横軸に身長、y:縦軸に体重、style:形、hue:色、
p=sns.scatterplot(x=height_box, y=weight_box, style=team_box, hue=team_box, palette='Paired')
sns.set_style("whitegrid", {'grid.linestyle': '--'})
#軸の名前
p.set_xlabel("身長", fontsize = 16)
p.set_ylabel("体重", fontsize = 16)
#なぜか下のコードをこのポジションに描かないと、日本語が表示できなかった
sns.set(font='IPAexGothic')
p.legend(loc = 2, bbox_to_anchor = (1,1))
plt.show()
plt.close()
コードを実行すると中日の選手だけのデータを可視化した図が作成されます。
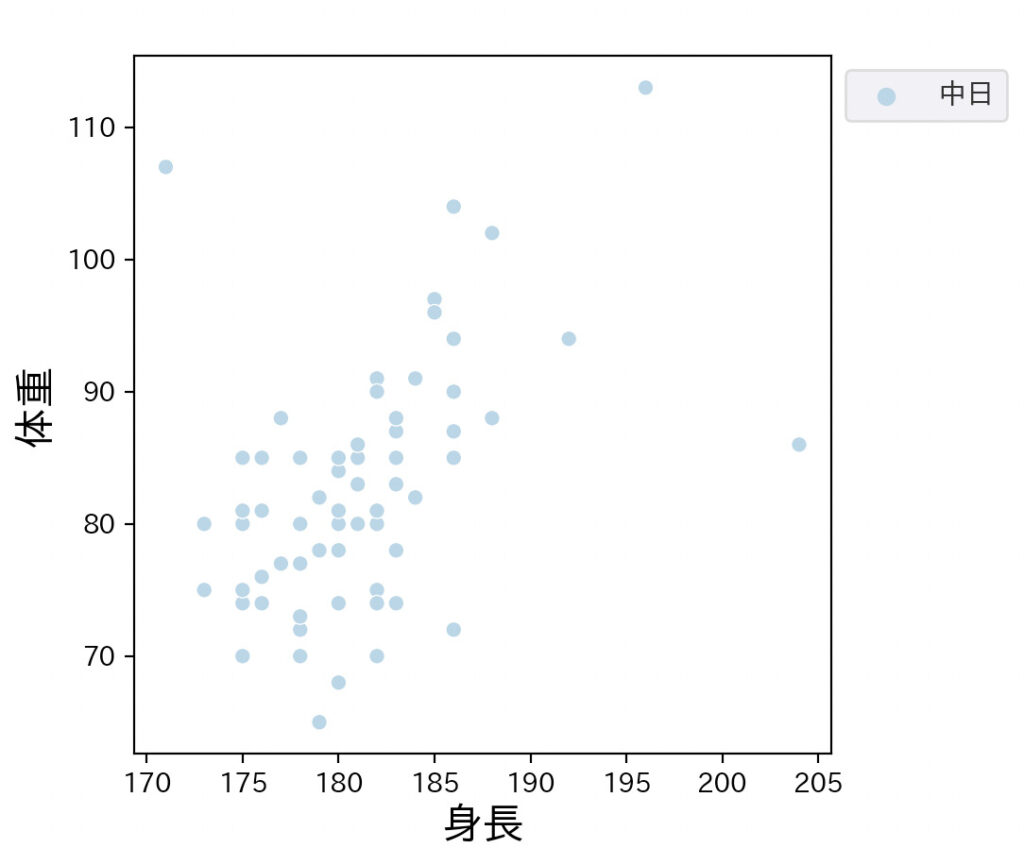
データを抽出している箇所は、実はこの1行だけです。
ch_df = df[df[‘球団’] == ‘中日’]
もしかしたら、他にも書き方があるかもしれないですが
こういう書き方があるよ〜などあればコメントで教えていただければ嬉しいです!!
おわりに
ここまで読んでいただき、ありがとうございました。
最近は連続でpandasに関する記事を書いてしまっておりますが
実は同じ職場のプログラミングが得意な人(存在が奇跡)がpandasを使っていたのを見て、記事を書いてみようという気分になったからでした!
昔は私はnumpyばっかり使っていたのですが、最近はpandasも使い方を覚えてきて
色々コードを書きやすくなってきました。
さて、もう今年も2ヶ月が終わってしまいましたね。
時の流れは早いものです。
年末に食べたおせちが懐かしい。
これを読んでいる方には、私と同じく早く長期休暇を望んでいる社会人も多いでしょう!!
まずはGW休みを目指してあと2ヶ月頑張りましょう!!
わたしもがんばりる。。。