この記事はこんな人におすすめ
・PythonによるTwitter APIの使い方を知りたい方
・Pythonライブラリのtweepyの扱い方を知りたい方
・tweepyで取得したデータをグラフで表現したい方
など
どうもこんにちは。
コンです。
今回はTwitterのAPIを使って自分のツイートを取得して、
seabornとpandasで可視化したいと思います。
ツイッターのAPIの取得方法に関してはこちらの記事が参考になるかと思います。
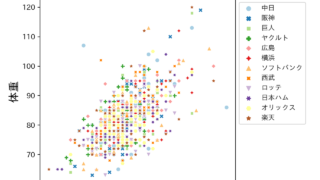
作成したグラフ

こんな感じのグラフになっております。
横軸が曜日で月〜日、縦軸が下から0時〜23時をで、
それぞれのマスにどれだけのツイートやリツイートしたかの数字を書いております。
特定の時間に多いですよね(笑)
実はこれはPythonで書かれた自動リツイートのプログラムを使っているからなんです。

あとは最近リコリス・リコイルのアニメにハマっていて
放送時間が土曜の23:30~だったので、土曜の深夜から日曜までツイートをガンガンしておりました。
そのあたりがしっかり可視化されてますね。
コード
def main():
dt_now = datetime.datetime.now()
print('データ取得', dt_now)
consumer_key = 'XXXXX'
consumer_secret = 'XXXXX'
access_token_key = 'XXXXX'
access_token_secret = 'XXXXX'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token_key, access_token_secret)
api = tweepy.API(auth)
my_user_id = api.verify_credentials().id_str
#自分のアカウントのツイートを取ってくる
statuses = tweepy.Cursor(api.user_timeline).items(3000)
data = collections.defaultdict(list)
#データを整形
for status in statuses:
t = status.created_at + datetime.timedelta(hours=9)
data['hour'].append(t.hour)
data['weekday'].append('Mon Tue Wed Thu Fri Sat Sun'.split()[t.weekday()]
)
data['hour'].extend(range(24))
data['weekday'].extend(['filler'] * 24)
df = pd.DataFrame(data)
#時刻と曜日ごとにカウント
tab = pd.crosstab(df.hour, df.weekday)
#indexとcolumnの順番を直す
tab = tab['Mon Tue Wed Thu Fri Sat Sun'.split()]
tab = tab.sort_index(ascending=False)
sns.heatmap(tab, annot=True, fmt='d', cbar=False, cmap=sns.light_palette("navy", as_cmap=True))
plt.title('time')
plt.xlabel('day')
plt.show()
plt.close()
main()早速コードの紹介です。
ポイントとしては
tweepy.Cursor(api.user_timeline)で自分のタイムラインを取得して
後ろのitems(3000)で3000件取得すると指定している点でしょうか。
今回調べてコードを書いたわけではなく、こちらの記事のコードを書き直したものになります。

7年前の記事だったので、色々と書き方が変わっているので
書き直して紹介させていただきました。
おわりに
ここまで読んでいただき、ありがとうございました。
今回はあまりコードの中身がどうなっているかとかまではあまり考えずに
さらっと実装いたしました。
もしなにかしら間違っていたら教えていただけると嬉しいです。
では!!