○PyCaretを試してみたい方
○回帰モデルの機械学習の勉強をしている方
○チュートリアルとは違うRegressionの例を探してる方
どうもこんにちは、コンです。
今回はTwitterなどでも少し話題になっている機械学習ライブラリ、PyCaretについて解説したいと思います。
PyCaretは、scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Opuna、Hyperopt、Ray など、いくつかの機械学習ライブラリをセットにしたライブラリだそうで、数行のコードでモデルの比較や、前処理を行えるそうです。
ただ、ニューラルネットワーク系はまだ実装されてなさそう。
個人的に自動モデル選択は興味があったので
Pycaretを使ってxsin(x)関数の回帰問題を解いてみたいと思います。
PyCaretについては日経ソフトウェアさんでも扱っています。
お題
PyCaretの公式サイトには保険のデータについて
年齢、性別、bmiなどのデータから保険料を出力する回帰モデルのチュートリアルが書かれています。
今回はそれとは少し違い、下記のようなy=xsin(x)関数にノイズを加えたデータ点80個から
PyCaretでモデルを作って、モデルがどうなっているかを見てみたいと思います。
PyCaretの実装
データ作成
PyCaretは基本的にPandasのデータフレームに対応している機械学習ライブラリなので
今回の予想お題であるxsin(x)+noiseのデータ作成もNumpyで作成しPandasのデータフレームに収納します。
下記はデータ作成用のコード。
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pd
#予測する関数
def test_function(x):
y = x*np.sin(x)
return y
#機械学習用データ作成
def dataset_maker(train_n):
#訓練データの生成
np.random.seed(seed=16)
x_train = np.random.rand(1, train_n)*10
noise_train = np.random.rand(1, train_n)-0.5
y_train = test_function(x_train)+noise_train
return x_train, y_train
def main():
x_train, y_train = dataset_maker(100)
train_data=pd.DataFrame(
data={'x_train': x_train.flatten(),
'y_train': y_train.flatten()}
)
if __name__ == '__main__':
main()PyCaretによるモデル比較
PyCaretはsetupとcompare_modelsのみの記述で18種類の機械学習のモデルを評価してくれます。
先ほどのプログラムのimportとmain()/の部分に追記して実行していきます。
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pd
from pycaret.regression import *
予測する関数
def test_function(x):
y = x*np.sin(x)
return y
#機械学習用データ作成
def dataset_maker(train_n):
#訓練データの生成
np.random.seed(seed=16)
x_train = np.random.rand(1, train_n)*10
noise_train = np.random.rand(1, train_n)-0.5
y_train = test_function(x_train)+noise_train
return x_train, y_train
def main():
x_train, y_train = dataset_maker(100)
train_data=pd.DataFrame(
data={'x_train': x_train.flatten(),
'y_train': y_train.flatten()}
)
s = setup(data=train_data, target = 'y_train', train_size=0.8)
best = compare_models()
if __name__ == '__main__':
main()上記を実行すると、上から順に指標の良いモデルが与えられる。

どうやらExtra Trees Regressorが良い性能らしい。
大変申し訳ないのですが、決定木のアルゴリズムの1種だよ。というくらいしか知らない。。。
また今度勉強しよ。
回帰モデルをプロットしてみる
Extra Trees Regressorが1番よさそうだとわかったので、xsin(x)と共にプロットしてみて
どれくらい予想できているのか可視化してみます。
今回はLightGBMと線形回帰についても可視化してみて、性能の違いを確認してみました。
また上で説明したコードに、可視化プログラムをmain()関数に追記します。
(これで今日のコード記入は終わり)
import numpy as np
import random
import matplotlib.pyplot as plt
import pandas as pd
from pycaret.regression import *
#予測する関数
def test_function(x):
y = x*np.sin(x)
return y
#機械学習用データ作成
def dataset_maker(train_n):
#訓練データの生成
np.random.seed(seed=16)
x_train = np.random.rand(1, train_n)*10
noise_train = np.random.rand(1, train_n)-0.5
y_train = test_function(x_train)+noise_train
return x_train, y_train
def main():
#データ生成
x_train, y_train = dataset_maker(100)
train_data=pd.DataFrame(
data={'x_train': x_train.flatten(),
'y_train': y_train.flatten()}
)
#モデル比較
s = setup(data=train_data, target = 'y_train', train_size=0.8)
best = compare_models()
x = np.linspace(0, 10, 500)
y = test_function(x)
#作成した回帰モデルをプロットする。
plot_data=pd.DataFrame(
data={'x_train': x,
'y_train': y}
)
predictions = predict_model(best, data=plot_data)
predictions.rename(columns={'prediction_label': 'Best_function'}, inplace=True)
#lightgbm
lightgbm = create_model('lightgbm')
predictions_lightgbm = predict_model(lightgbm, data=plot_data)
predictions_lightgbm.rename(columns={'prediction_label': 'Lightgbm'}, inplace=True)
#線形回帰
lr = create_model('lr')
predictions_lr = predict_model(lr, data=plot_data)
predictions_lr.rename(columns={'prediction_label': 'Linear Regression'}, inplace=True)
#pandasのフレームを結合
df1=pd.merge(predictions, predictions_lightgbm, how='right')
df2=pd.merge(df1, predictions_lr, how='right')
df2.rename(columns={'y_train': 'xsin(x)'}, inplace=True)
fig, ax = plt.subplots()
df2.plot(x="x_train", y=['xsin(x)', 'Best_function','Lightgbm','Linear Regression'], ax=ax)
ax.scatter(x_train, y_train, label='train data')
ax.set_xlabel("x")
ax.set_ylabel("y")
plt.show()
plt.close()
if __name__ == '__main__':
main()今回のコードで個人的に難しかったのがPandasのデータフレームの取り扱いでした。
全然慣れていなかったため、列の名前を何度もrenameしております。
(読みにくくて、ごめんなさい。。。)
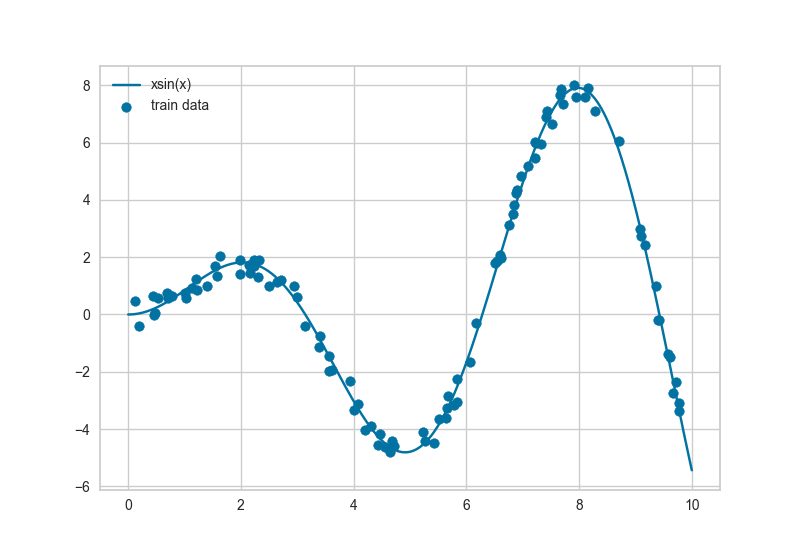
このコードを実行すると下図のように、xsin(x)関数と訓練に使用したデータ、Best function(Extra Trees Regressor)、LightGBM、線形回帰の回帰モデルのプロットが出力されます。
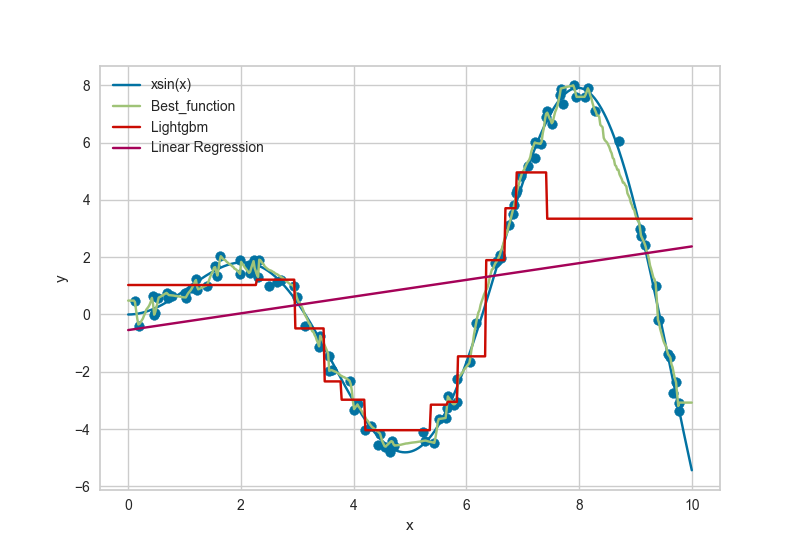
この結果からは確かにExtra Trees Regressorが他のモデルと比べて予測精度の高い回帰モデルのような気がしますね。
でも
例えばExtra Treesは良い予想モデルだけどx=0付近の値はあまり予想できていないのでは?って思ったり。
でもxが6~7にかけてはかなりスムーズな関数になっていて、良い感じなのでは?と思ったり。
機械学習の予測モデルの評価は難しい。
おわりに
ここまで読んでいただき、誠にありがとうございます。
今回はPyCaretの実装だったのですが、1番苦戦したのはPandasでした。
いつもNumpyでほとんどの事柄を行ってしまうため、Pandasの書き方わからんな〜と言いながら
フレームを結合するのに1時間くらい使ってました。
いつもと違うことをやるのも、また勉強で楽しかったです。
また機械学習のコードについて書いていきたいと思います。