Pythonで手取り早くシンプルな機械学習用のデータを作成したい方
どうもこんにちは。コンです。
scikit-learnは、Pythonのオープンソース機械学習ライブラリの一つです。2007年からGoogleが開発に関わっていて、機械学習を勉強すると絶対1回は聞いた事のあると思います。
線形回帰・SVM・ランダムフォレストなど、様々な手法を簡単に実装できるライブラリなのですが
データセット自体もこのライブラリを使うと簡単に作ることができたので紹介いたします。
分類用のデータセット
ここでは簡単な2次元上へプロットされた分類用のデータを紹介します。
分類の区別は色で表現しています。
2クラス分類
まずは2クラス分類のコードの紹介から。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
plt.title("One informative feature, one cluster per class", fontsize="small")
X1, Y1 = make_classification(
n_features=2, n_informative=1, n_redundant=0, n_clusters_per_class=1, n_classes=2
)
plt.scatter(X1[:, 0], X1[:, 1], marker="o", c=Y1, s=25, edgecolor="k")
plt.show()
このコードではmake_classificationというsikit-learnの関数を使っております。
パラメータの説明がsikit-learnの書き方だと難しいのですが、正規分布のクラスターが
- n_features:次元数のパラメータ
- n_informative:データを作成するのに使った次元数(有益な次元数)
- n_redundant:冗長という意味らしいが、線形従属かどうかを調整するパラメータ
- n_clusters_per_class:各クラスのクラスターの数
らしいです。n_informativeが少し難しくて、自分でもまだ分かっていないです。(すみません)
またY1は0または1のnumpy.ndarrayとして出力されてます。
(例えば[0, 1, 0, 0, 1, 0 ….. ,0]みたいな)
多クラス分類
多クラス分類の場合にもmake_classification関数は使えます。
4つのクラス分類データを作成した時のコードと結果は以下のようになります。
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
plt.title("Two informative feature, one cluster per class", fontsize="small")
X1, Y1 = make_classification(
n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, n_classes=4
)
plt.scatter(X1[:, 0], X1[:, 1], marker="o", c=Y1, s=25, edgecolor="k")
plt.show()
多クラス分類の時のY1の値は0, 1, 2, 3の4種類整数のnumpy.ndarrayとして出力されてます。
(例えば[1, 1, 0, 3, 1, 2 ….. ,2]みたいな)
回帰用のデータセット
回帰(予測)用のデータセットも作成できます。
分類の時と同じようなコードで出力できるので、簡単です。
単回帰分析用のデータ作成
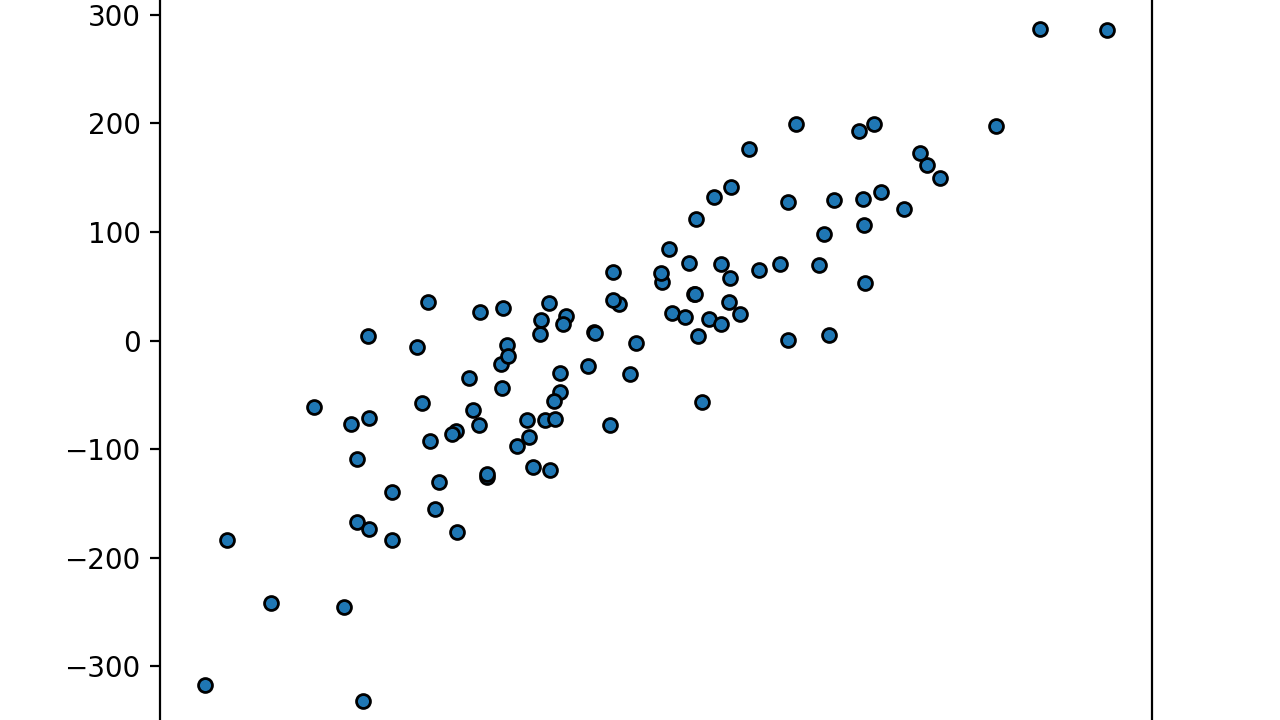
最初は1つの変数(横軸の変数)だけで、縦軸の変数を予測できるデータセットを作成するコード。
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
plt.title("Regression data 2-D", fontsize="small")
X1, Y1 = make_regression(
n_features=2, n_informative=2, n_targets=1
)
plt.scatter(X1[:, 0], Y1, marker="o", s=25, edgecolor="k")
plt.show()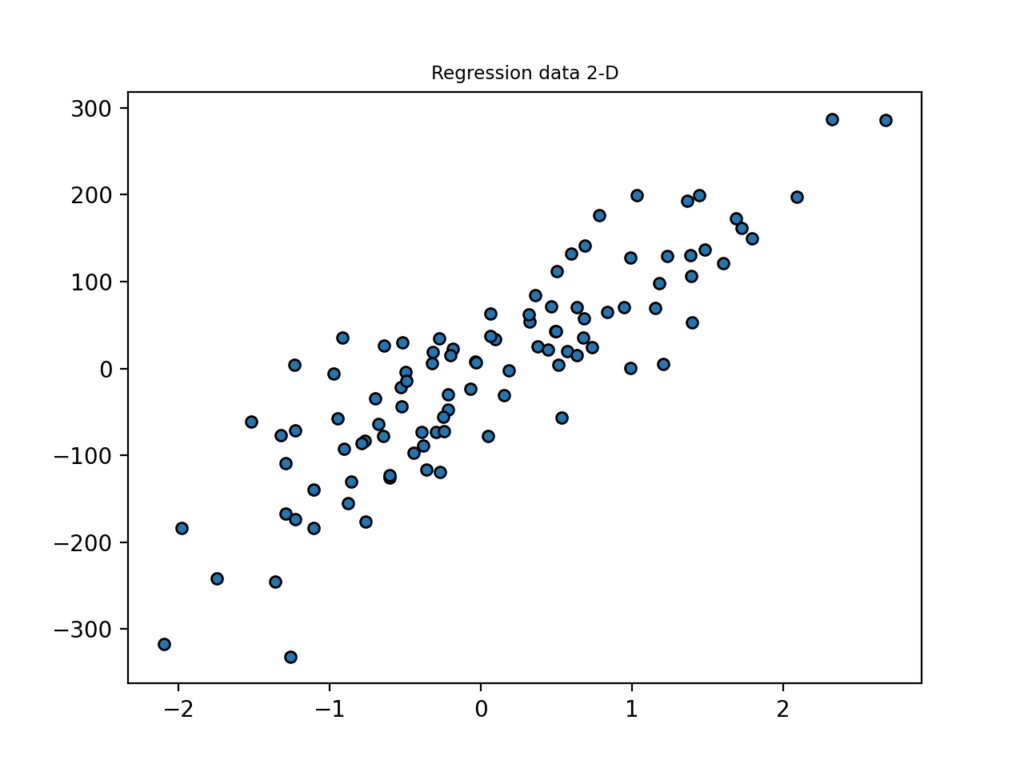
重回帰分析用のデータ作成
複数の特徴量から、何かを予測するデータセットも作成可能。
下記は例の1つで、2つの特徴量から1つの出力を回帰するデータ生成のコード。
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.datasets import make_regression
fig = plt.figure(figsize = (8, 8))
# 3DAxesを追加
ax = fig.add_subplot(111, projection='3d')
plt.title("Regression data 3-D", fontsize="small")
X1, Y1 = make_regression(
n_features=2, n_informative=2, n_targets=1
)
ax.scatter(X1[:, 0], X1[:, 1], Y1, marker="o", s=25, edgecolor="k")
plt.show()
print('X1', X1)
print('Y1', Y1)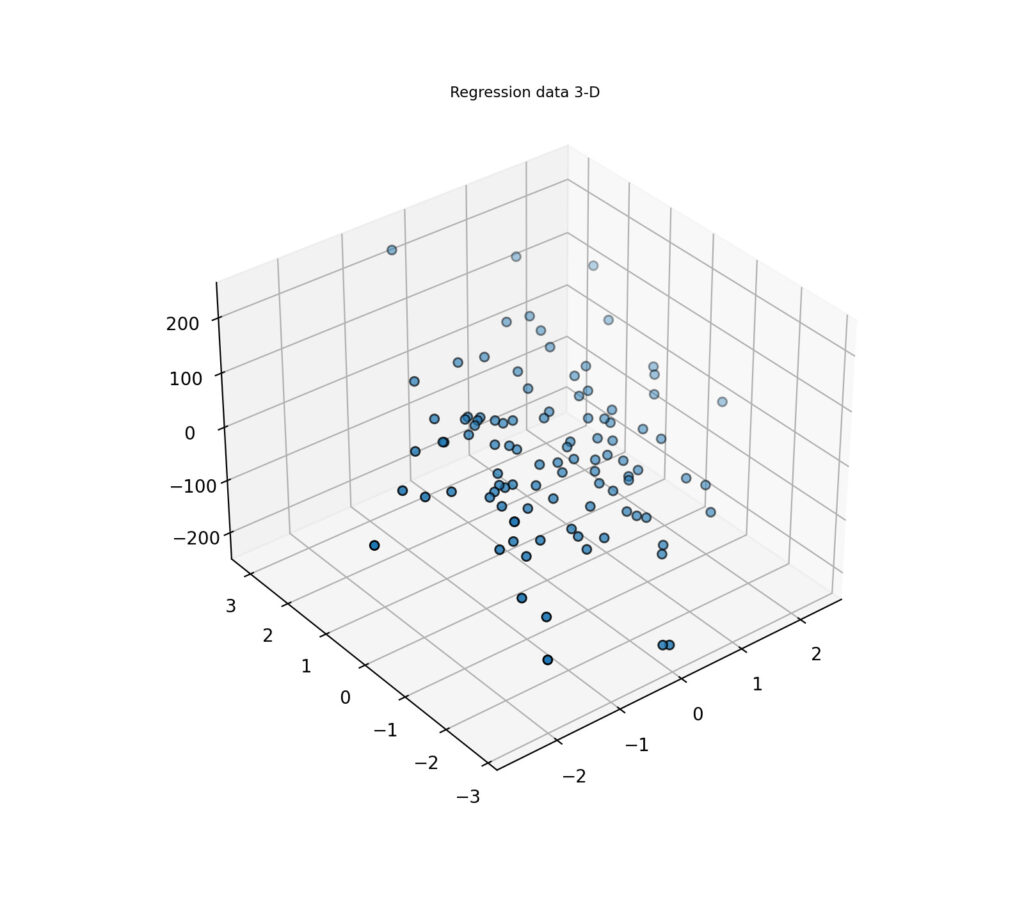
3次元データにすると、少し見にくい。
おわりに
今回は簡単な機械学習の練習用データの作成方法について紹介しました。
毎回ランダムに作成することだけでなく、作ったデータをCSVファイル等に保存も可能です。
こういうデータセットの使い所は、色々な機械学習の手法を試すことに使うと
手法について理解が深まるので、今後の色々試行きたいと思います。
ではでは。