・画像中の文字を認識したい人
・ EasyOCRの実装例について知りたい方
など
画像中の文字を簡単に認識できる方法を調べていると
EasyOCRという、簡単に実装できることを全面に名前で表現しているPythonライブラリを見つけてしまったので紹介させていただきます。
実際使ってみて、とても良いいなと思ったので紹介させてください。
EasyOCRはPythonで書かれたオープンソースの画像処理ライブラリであり、画像中の文字を認識してくれる機能があります。
本記事では、EasyOCRの使い方や機能について詳しく説明し、実際に文字認識を行う手順を紹介します。
インストール
Pythonのバージョンはあまり指定されていませんが、 Python 3.8 を今回は使用しました。
インストールはpipでインストールします。
pip install easyocr
今回私はCPUのマシンを使って色々試しましたが、数秒で結果が出力されるので満足してます。
認識する文字
今回は用意した文字はこちら。

手書きのフォントの画像ですね。
この画像を読み込み、どんな文字が書かれているかを見ます。
名前はsample.pngとしました。
Pythonコード
サンプルプログラム(その1)
sample.pngと以下のPythonファイルを同じディレクトリに置いて、Pythonを実行します。
import easyocr
reader = easyocr.Reader(['ja', 'en']) # this needs to run only once to load the model into memory
result = reader.readtext('sample.png')
print(result)
上記のコードを実行すると、コマンドプロンプトに画像中の認識した文字が出力されます。
ポイントになるのがeasyocr.Reader([‘ja’, ‘en’])の部分です。
‘ja’, ‘en’がそれぞれ言語コードと呼ばれるもので、事前に画像中の文字の種類を指定します。
他の文字コードはこちらにあります。
以下が実行結果になります。
少し読みにくいですが、実際にコマンドプロンプトに出力されるスクリーンショットは以下のようになります。

読みにくので文字にすると
[([[69, 67], [449, 67], [449, 151], [69, 151]], ‘空とひこうき’, 0.8749…),
([[557, 61], [973, 151], [557, 145], [869, 145]], ‘花とちょうちょ’, 0.811386),
…..
([[60, 408], [493, 408], [493, 486], [60, 486]], ‘123456789’, 0.9996142015265052),
([[553, 406], [973, 406], [973, 486], [553, 486]], ‘123456789’, 0.9999434939985133)]
という出力が得られました。
得られたリスト型のデータの中身がタプルになっており、
タプルの中身が
(文字の座標のリスト[[左上][右上][右下][左下]], 検出した文字, 確信度)
のようになってます。
やってみた結果としては
どの文字も確信度0.5以上で出力してますね。
めっちゃしゅごい。
特に日本語はしっかり判別してますね。
サンプルコード(その2)
今度は、検出した結果を使って
画像中の検出した文字を四角で囲み、検出結果・確信度を書き込むようなものを作っていきたいと思います。
上の画像を出力するコードが下のようになります。
import easyocr
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
#画像中に日本語を記入する関数
def putText_japanese(img, text, point, size, color):
font = ImageFont.truetype('ヒラギノ角ゴシック W8.ttc')
#imgをndarrayからPILに変換
img_pil = Image.fromarray(img)
#drawインスタンス生成
draw = ImageDraw.Draw(img_pil)
#テキスト描画
draw.text(point, text, fill=color, font=font)
#PILからndarrayに変換して返す
return np.array(img_pil)
#メインの処理
def main():
reader = easyocr.Reader(['ja', 'en']) # this needs to run only once to load the model into memory
result = reader.readtext('leter.png')
###
im = cv2.imread('leter.png')
for element in result:
#認識した文字を青で囲む
cv2.rectangle(im, element[0][0], element[0] , (255, 0, 0))
#認識した文字と確信度を赤で表示
im=putText_japanese(im, element
, (255, 0, 0))
#認識した文字と確信度を赤で表示
im=putText_japanese(im, element +':'+str(round(element, 2)), element[0][0], 100, (10, 10, 255))
cv2.imshow('result', im)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
+':'+str(round(element, 2)), element[0][0], 100, (10, 10, 255))
cv2.imshow('result', im)
cv2.waitKey()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
実行すると以下のような結果がえられます。
どの文字もしっかりと、認識れていることがわかりますね。
ほんとにしゅごい。

コードを書く際に大変だったのが、画像中に日本語を書くところ点でした。
openCVのメソッドであるcv2.putTextで日本語で文字列を描画しようとすると???...?という表示になってしまいます。
なので、フォントを指定して、PILで表示させる方法を
ものものテックさんというブログ様を参考に書かせてもらいました、
使われている技術
EasyOCRは以下の画像のように、複数のアルゴリズムを用いて
文字を検出しています。
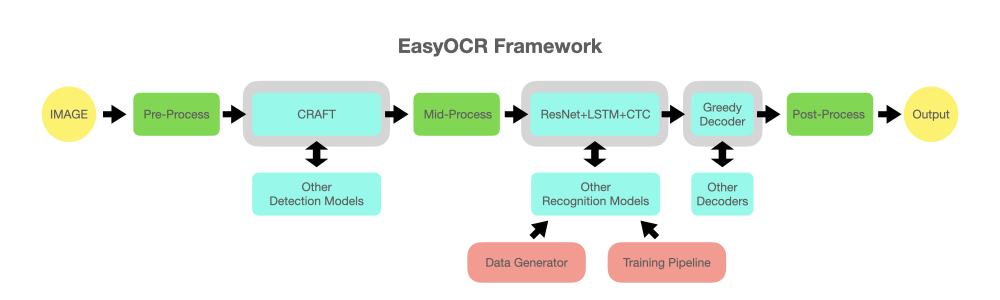
難しく書いているかもしれませんが、大まかな手順としては
①CRAFTで文字が書いてあるところを検出する。
②CRNN(ResNet+LSTM+CTC)で、どんな文字が書いてあるか認識する。
で画像中の文字を認識します。
①CRAFT
CRFTは2019年に発表された、手法です。
各文字と文字の間隔を探索してを、文字をワンフレーズで出力する手法です。
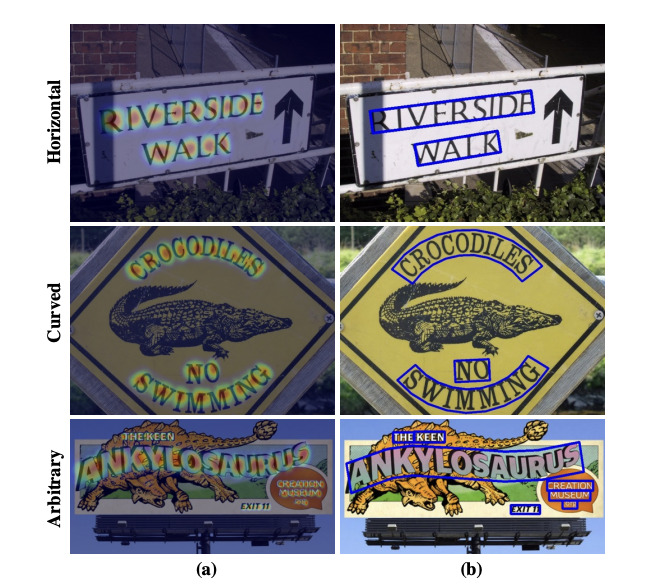
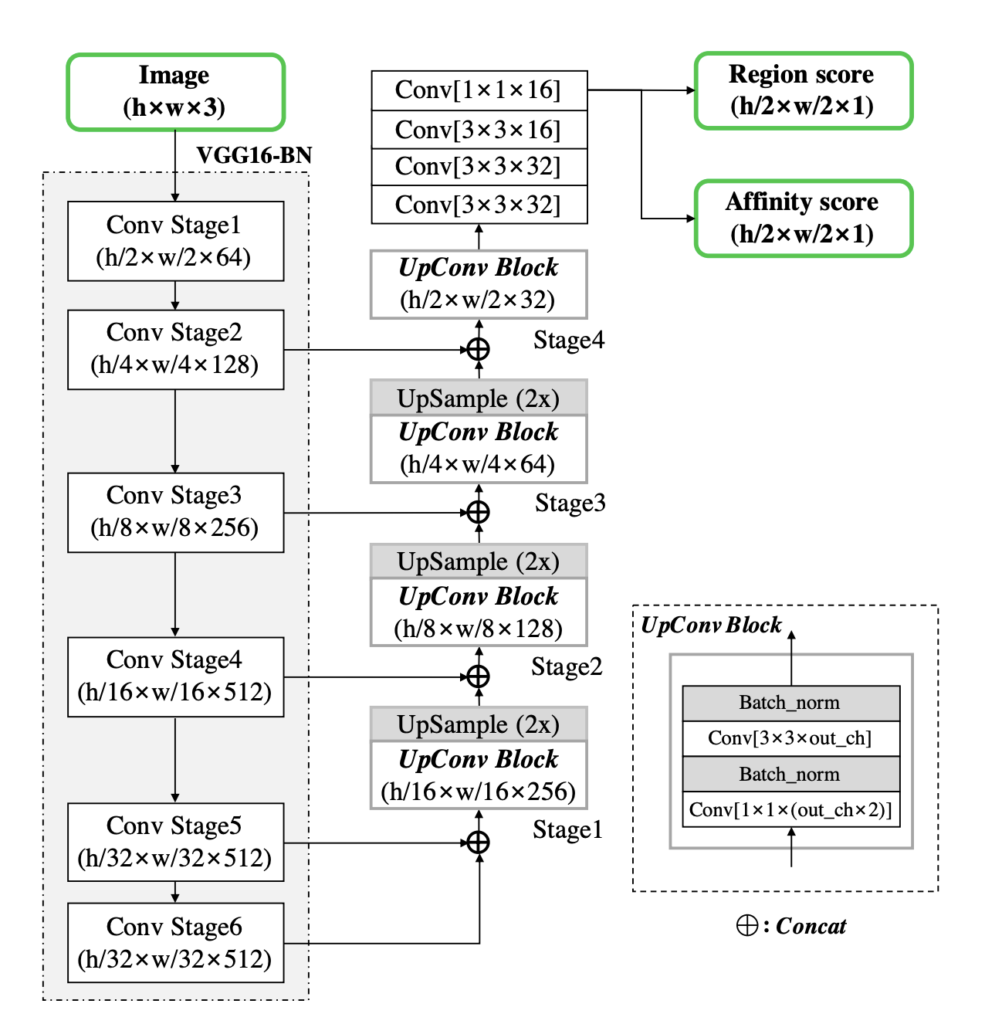
モデルの構造としては、U-netのような構造をしています。
出力は、文字単位のヒートマップをRegion score、文字間のヒートマップをAffinity scoreとして出力します。
弱教師あり学習の手法を使っているですが
詳しくは以下のQitaの記事様が丁寧に解説していたので割愛させてください。

②CRNN
こちらは2015年に発表されている
CNNとRNNの要素を合わせて、連続文字を出力する手法。
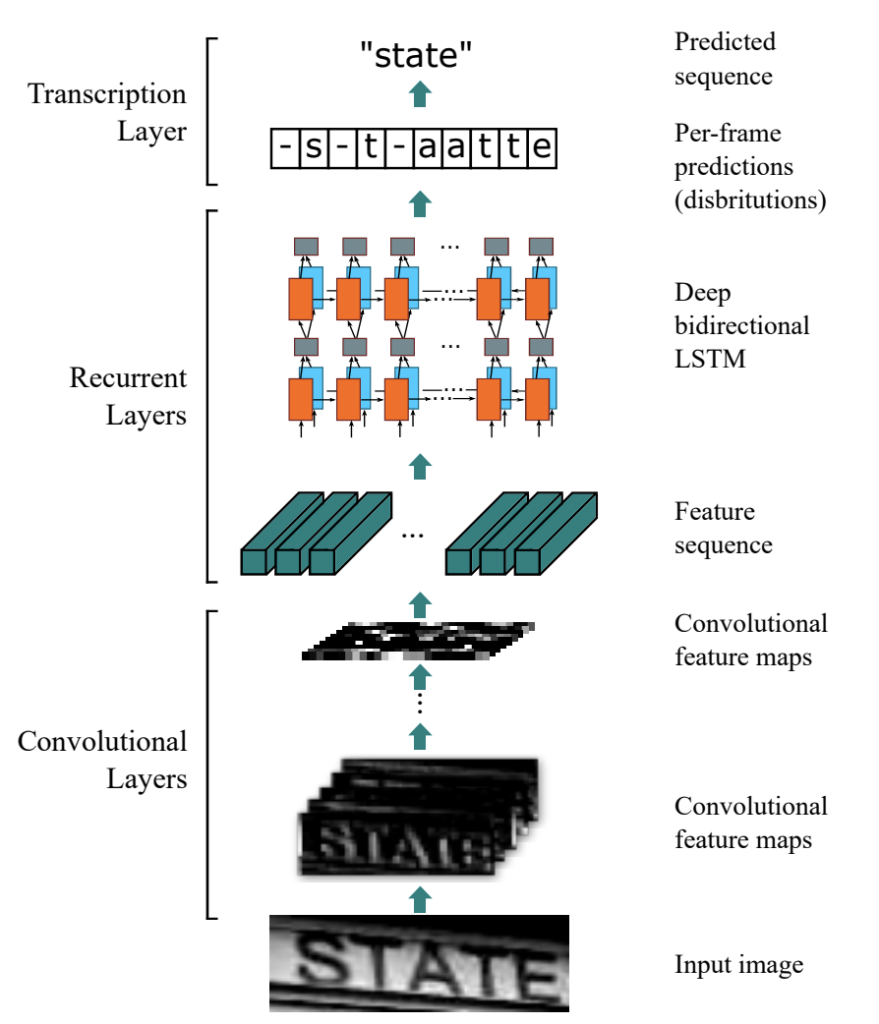
私がわかっていないことなのですが。。。
この手法で使われているCTC Lossを評価することで、
上の図の-s-t-aatteからstateを出力する??らしいです。
この分野は全然今まで勉強できてないので、今後勉強していきます。
おわりに
ここまで読んでいただき、ありがとうございました。
OCRのアルゴリズムの良いところは
会社でも使えるシーンが沢山あるところですね。
会社の書類、作っている製品の番号確認など使えるシーンが沢山あると思います。
また今回のEasyOCRは学習済みモデルなので、導入者が維持管理しなくてもいいので
機械学習エンジニアじゃなくても導入しやすいですね。
今後も便利なライブラリや手法があれば紹介したいと思います!!
それでは。