どうも、コンです。
センサーから吐かれた CSV を pandas で読もうとしたら UnicodeDecodeError。
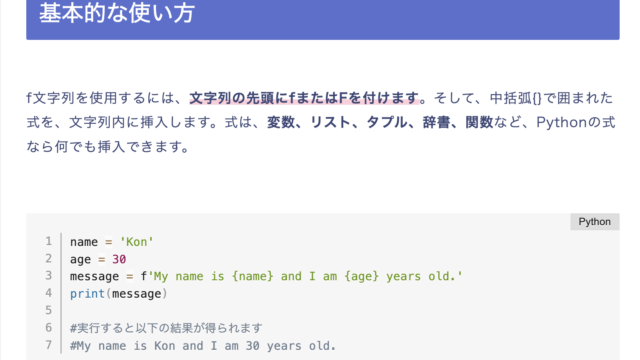
こんな感じのCSVです。

原因を辿っていったら、どうも犯人は ℃の1文字みたいでした。
Python で日本語混じりの CSV を扱うとぶつかる定番の事故らいです。
この記事では、℃ を含む CSV をネタに「読めない/読めても壊れている」ケースを再現して、pandas でどう対処するかをまとめます。
事件:pd.read_csv で UnicodeDecodeError
あるセンサーのログ CSV を、いつもの調子で pd.read_csv に渡したらこうなりました。
import pandas as pd
df = pd.read_csv("sensor.csv")
# UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8e in position 49: invalid start byte「byte 0x8e」というあたりが手がかりです。49 バイト目に UTF-8 として解釈できないバイト(0x8e)があった、と言ってるエラーらしいです。
実はこの 0x8e、CP932 で「℃」を表すバイト列の一部でした。
検証用に同じCSVを4つの文字コードで用意した
本題に入る前に、いくつかの文字コードで「同じ内容の CSV」を用意しておきます。読み込み側のふるまいを確かめるとき、書き込み側を揃えておくと比較が楽になるからです。
用意するのは、こんな3行のCSVです。
timestamp,sensor,temperature
2026-04-19 10:00:00,室温センサー,23.5℃
2026-04-19 10:01:00,室温センサー,23.6℃
2026-04-19 10:02:00,外気温センサー,18.2℃これを、4種類の文字コードで書き出します。
- utf8.csv:UTF-8 — Web 系ではこれが標準
- utf8_excel.csv:UTF-8 — ただし Excel が日本語UTF-8で保存するときに付ける「先頭の小さな目印(3バイト)」付きのバージョン
- cp932.csv:CP932(Windows の Shift-JIS 拡張)— 日本語 Excel が一番よく吐くやつ
- shift_jis.csv:純粋な Shift-JIS — レガシー業務システムで稀に見る
書き出しコードはこれだけです。
import pandas as pd
df = pd.DataFrame({
"timestamp": ["2026-04-19 10:00:00", "2026-04-19 10:01:00", "2026-04-19 10:02:00"],
"sensor": ["室温センサー", "室温センサー", "外気温センサー"],
"temperature": ["23.5℃", "23.6℃", "18.2℃"],
})
for filename, enc in {
"utf8.csv": "utf-8",
"utf8_excel.csv": "utf-8-sig",
"cp932.csv": "cp932",
"shift_jis.csv": "shift_jis",
}.items():
df.to_csv(filename, index=False, encoding=enc)これで4ファイル揃いました。準備完了です。
pd.read_csv で何が起きるか試す
まず、encoding を指定せずに各ファイルを読んでみるとどうなるかです。pandas のデフォルトは UTF-8 なので、UTF-8 のファイルは通って CP932 系はエラーになる、はず。
import pandas as pd
for f in ["utf8.csv", "utf8_excel.csv", "cp932.csv", "shift_jis.csv"]:
try:
df = pd.read_csv(f)
print(f"✓ {f} → 読めた")
except UnicodeDecodeError as e:
print(f"✗ {f} → UnicodeDecodeError: byte 0x{e.object[e.start]:02x} ({e.reason})")実行結果はこんな感じ。
✓ utf8.csv → 読めた
✓ utf8_excel.csv → 読めた
✗ cp932.csv → UnicodeDecodeError: byte 0x8e (invalid start byte)
✗ shift_jis.csv → UnicodeDecodeError: byte 0x8e (invalid start byte)予想通り、CP932 系の2ファイルは byte 0x8e で読み込みに失敗します。これが冒頭の「℃ でエラーになる」の正体です。
では、encoding を明示的に指定して読み直すとどうなるか。
df = pd.read_csv("cp932.csv", encoding="cp932")
print(df)
# timestamp sensor temperature
# 0 2026-04-19 10:00:00 室温センサー 23.5℃
# 1 2026-04-19 10:01:00 室温センサー 23.6℃
# 2 2026-04-19 10:02:00 外気温センサー 18.2℃無事読めました。「とりあえず Excel が吐いた CSV は CP932」と覚えておけば、日常はだいたいこれで突破できます。
Excel が UTF-8 で保存したファイルの場合
Excel で「CSV UTF-8」として保存すると、ファイルの先頭に3バイトの小さな目印が勝手に付きます。これがあると、昔の pandas や Python 標準の open() ではファイル先頭の列名が壊れてしまい、df["timestamp"] で KeyError になる、という事故がよく起きていました。
これを正しく扱うための encoding が utf-8-sig です(”sig” は signature の略で、その目印のこと)。試しに utf8_excel.csv を3パターンで読み比べてみます。
import pandas as pd
# ① encoding 未指定(デフォルト utf-8)
df1 = pd.read_csv("utf8_excel.csv")
print(list(df1.columns)) # ['timestamp', 'sensor', 'temperature']
# ② encoding="utf-8" を明示
df2 = pd.read_csv("utf8_excel.csv", encoding="utf-8")
print(list(df2.columns)) # ['timestamp', 'sensor', 'temperature']
# ③ encoding="utf-8-sig" を指定(本来の正解)
df3 = pd.read_csv("utf8_excel.csv", encoding="utf-8-sig")
print(list(df3.columns)) # ['timestamp', 'sensor', 'temperature']結論として、pandas 2.x では3パターンとも普通に読めます。pandas 側が先頭の目印を自動で取り除いてくれるようになっているからです。なので、Excel UTF-8 を渡されたときも基本的には深く考えず pd.read_csv で大丈夫。心配なら encoding="utf-8-sig" を明示しておくと、古い環境や標準の open() でファイルを直接読むときも安全です。
どうしても判別がつかないときの最終手段
どうしても文字コードがわからないときの最終手段として、encoding_errors="replace" や "ignore" で強引に読む手もあります。が、これは本当に最終手段で、結果を見ると諦めたほうがいいことが分かります。
df1 = pd.read_csv("cp932.csv", encoding="utf-8", encoding_errors="replace")
print(df1.iloc[0].to_dict())
# {'sensor': '�����Z���T�[', 'temperature': '23.5��'} ← 文字化け文字
df2 = pd.read_csv("cp932.csv", encoding="utf-8", encoding_errors="ignore")
print(df2.iloc[0].to_dict())
# {'sensor': 'ZT[', 'temperature': '23.5'} ← データが無音で消えるとくに ignore は危険です。「室温センサー」が「ZT[」になって、エラーも警告も出ません。後段の集計が静かにバグるパターンの代表格なので、デバッグ目的以外では使わないほうが無難です。
読めても壊れている:℃ と °C は別の文字
文字コードを正しく指定して、めでたくCSVが読めた。これで安心、と思ったらまだ罠があります。「℃」と「°C」は見た目がほぼ同じだけど、Python から見ると別の文字列なんです。
- ℃:Unicode の
U+2103(DEGREE CELSIUS)。1文字 - °C:
U+00B0(DEGREE SIGN)+'C'。2文字
Python で比較するとこうなります。
a = "23.5℃" # U+2103
b = "23.5°C" # U+00B0 + 'C'
print(a == b) # False
print(len(a), len(b)) # 5 6これの何が困るかというと、センサーや機材ごとに表記がバラバラなデータを扱うときに集計から漏れる行が出ます。たとえば、こんな DataFrame があったとします。
import pandas as pd
df = pd.DataFrame({
"sensor": ["A", "A", "A", "B", "B"],
"temperature": ["23.5℃", "23.6℃", "23.7℃", "18.2°C", "18.3°C"],
# ↑ U+2103 ↑ U+00B0 + 'C'
})
# 「℃」を含む行だけ抽出してみる
hit = df[df["temperature"].str.contains("℃")]
print(len(hit)) # 3 ← 全5行のはずが3行しかヒットしない「全件℃なんだから5行返るだろう」と思って書くと、しれっと °C 表記の2行が抜け落ちます。エラーも警告もないので気づきにくく、月次集計の値がなぜか合わない…みたいな話につながります。
救世主:NFKC 正規化で表記を揃える
こういう「見た目は同じだけど内部表現が違う」問題に対しては、Unicode 正規化(NFKC)という標準的な処方箋があります。NFKC は「見た目が同じ字をひとつの形に揃える」正規化方式で、℃ は °C に分解されます。
pandas の Series なら .str.normalize("NFKC") 一発で全行に適用できます。
df["temperature_norm"] = df["temperature"].str.normalize("NFKC")
print(df)
# sensor temperature temperature_norm
# 0 A 23.5℃ 23.5°C
# 1 A 23.6℃ 23.6°C
# 2 A 23.7℃ 23.7°C
# 3 B 18.2°C 18.2°C
# 4 B 18.3°C 18.3°C
# 正規化後ならどちらの表記でも揃う
hit = df[df["temperature_norm"].str.contains("°C")]
print(len(hit)) # 5 ← 全行ヒットポイントは、℃(U+2103)が NFKC 正規化で「°」+「C」に分解されること。元から「°C」で書かれていた行は変わらないので、両方の表記が同じ形に揃います。
単位を外して数値にする定石
表記が揃ったら、あとは「℃ / °C」を取り除いて float に変換すれば集計に使えます。NFKC 正規化と組み合わせて、こんな1チェーンで書けます。
df["temp_num"] = (
df["temperature"]
.str.normalize("NFKC") # ① ℃ → °C に統一
.str.replace("°C", "", regex=False) # ② 単位を取り除く
.astype(float) # ③ float に変換
)
print(df["temp_num"].mean()) # 21.46正規化 → 単位除去 → 型変換の3段。℃ と °C のどちらの表記が混じっていても、これで安全に数値化できます。「℃ を str.replace で消す」だけだと °C 表記の行で ValueError になるので、正規化を最初に挟むのがコツです。
まとめ:CSVを安全に読むための心得
℃ を入り口に、Pythonで日本語CSVを扱うときの定番の罠を一通り見てきました。最後に、実務で使える形でまとめておきます。
- UnicodeDecodeError が出たら、まず
encoding="cp932"を試す。日本語 Excel から出力した CSV はだいたいこれで通る - Excel が「UTF-8」で保存したファイルは
encoding="utf-8-sig"が無難。pandas 2.x なら"utf-8"でも読めるが、明示しておくと古い環境でも安全 encoding_errors="ignore"は最終手段。エラーを消す代わりにデータを無音で失うので、本番処理では使わない- 読み込み直後に
.str.normalize("NFKC")を挟む癖をつける。℃ vs °C のような「見た目は同じだけど別文字」事故が一発で消える
「℃の入った CSV が読めない」が、実は 文字コード ・ Unicode 正規化 ・ 表記揺れという3つの別レイヤの問題が重なった現象だった、というのが個人的に面白かった部分です。1度ハマって対処を覚えてしまえば、次から同じ事故は起きないので、ぜひ手元で試してみてください。
ここまで読んでいただきありがとうございました。それでは、また。