Pythonを使ってwebに掲載してある情報の取得方法を知りたい方
どうもこんにちは!!
コンです。
久しぶりに色々なフリーランスサイトを見てたのですが
結構多くの会社さんが、web上の情報収集を依頼しております。
例えばこんな案件が多いです。
【案件】
リストに記載されたキーワードをGoogleで検索して、検索結果をcsvファイルに保存するプログラムの作成
【報酬】
1万円
結構安い案件なのですが、この手の依頼は定期的にあるので
お小遣い稼ぎにはちょうどいいと感じております。
このお題をクリアするにはいくつかの手順があります。
それをまとめると以下のようになります。
- Pythonでスクレイピングできる環境を構築する。
- Pythonで指定のキーワード
- ②の結果をcsvファイルに保存する。
①に関しては、以下のリンクでお話させていただいているので、もしお時間あればご確認ください(^ ^)

今回は上記の②以降について書いていこうと思います。
1. プログラムコード
②、③の内容なので特にお題設定はせず、早速コードの紹介に移らせていただきますね。
1. Chromeを起動する
まずはChromeを立ち上げましょう!!
以下はそのコードになります。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import chromedriver_binary
import time
from selenium.webdriver.common.by import By
import numpy as np
######seleniumを使うための設定######
INTERVAL = 3
URL = "https://www.google.com/"
driver = webdriver.Chrome()
driver.maximize_window()
time.sleep(INTERVAL)
driver.get(URL)
time.sleep(INTERVAL)このあたりは、色々なサイトでも紹介されている内容なのですが
time.sleepという、一時的にプログラムの実行を中止する文も入ってます。
3秒も待つ必要はないかもしれませんが
この文があるので、サイトへのアクセス時間を稼いでおります。
2. 立ち上げた Chromeで検索を行う
次に検索を実行するコードになります。
#検索したいワードを入力
search_word = '工場プログラマー コン'
#文字を入力して検索
driver.find_element('name', 'q').send_keys(search_word + Keys.ENTER)
#検索を実行
time.sleep(5)まず前半のdriver.find_element(‘name’, ‘q’).send_keys(search_word + Keys.ENTER)
について。
find_element(‘name’, ‘q’)で、nameが’q’の要素を探し
send_keys(search_word + Keys.ENTER)で検索ワードを入力し、エンターキーを押す
そんなプログラムになります。
HTMLの要素の探し方
私のように普段web系のエンジニアでは無い人、Pythonでプログラミングを始めたばかりの人に難しいこと
それは。。。
要素を指定すること!!!
ここでは’name’や’q’ですね。
何故ならば、HTMLの要素を把握することが必要だからです。
Macユーザーの方ならChromeでは、option+ommand+Iでディベロッパーツールを開くことができ、ディベロッパーツールのElementsから各要素を確認することができます。
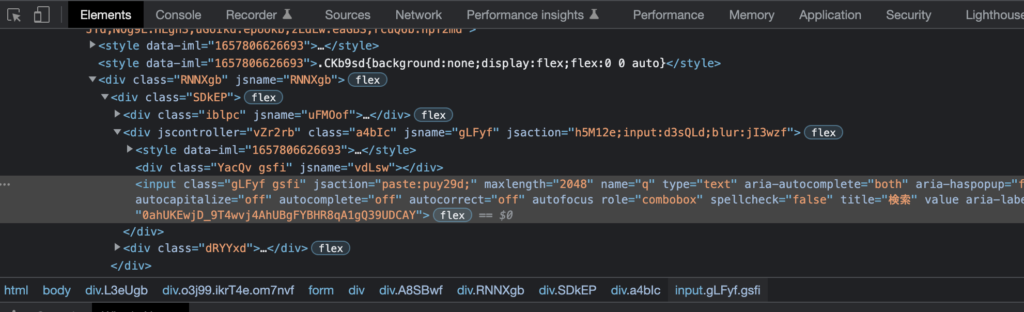
今回はGoogleの検索ボックスの箇所の名前を探します。
そんな時はデベロッパーツールの左上のセレクトモードを押します。
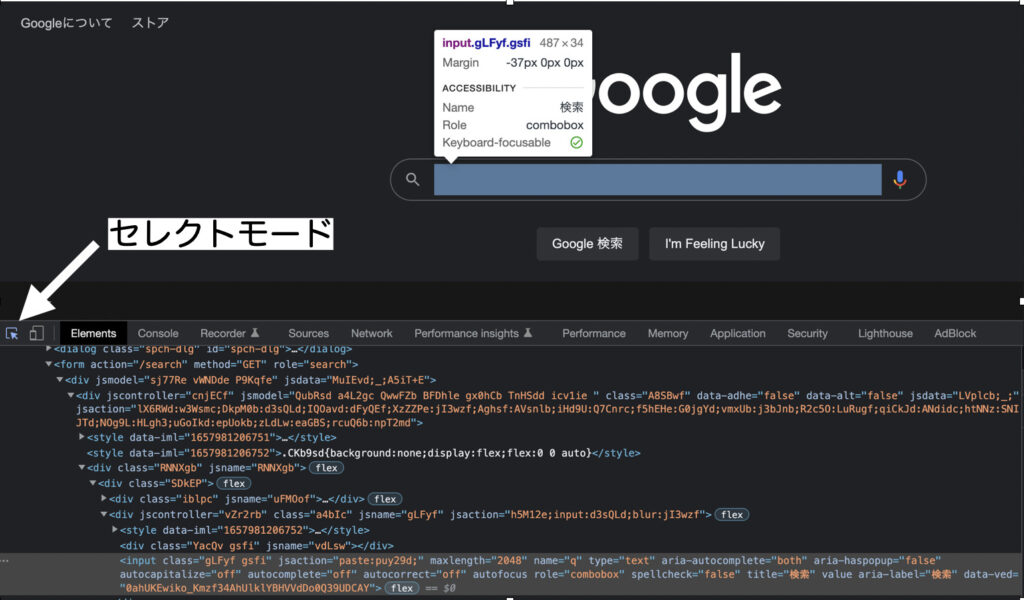
セレクトモードを押したら、
webページ上にカーソルを動かすだけで、該当箇所のHTMLのコードが示されるようになります。
今回はGoogleの検索画面を開いた後、name属性が’q’の要素に検索文字列を入力しています。
’q’は検索テキストボックスをクリックすることで検索が走ります。
3. 検索結果をリスト化する
ここまでできるようになれば、後はPythonの基本になりますね。
#検索結果の一覧を取得する
results = []
flag = False
while True:
g_ary = driver.find_elements_by_class_name('g')
for g in g_ary:
result = {}
result['url'] = g.find_element_by_class_name('yuRUbf').find_element_by_tag_name('a').get_attribute('href')
result['title'] = g.find_element_by_tag_name('h3').text
results.append(result)
if len(results) >= 20: #抽出する件数を指定
flag = True
break
if flag:
break
driver.find_element_by_id('pnnext').click()
time.sleep(INTERVAL)
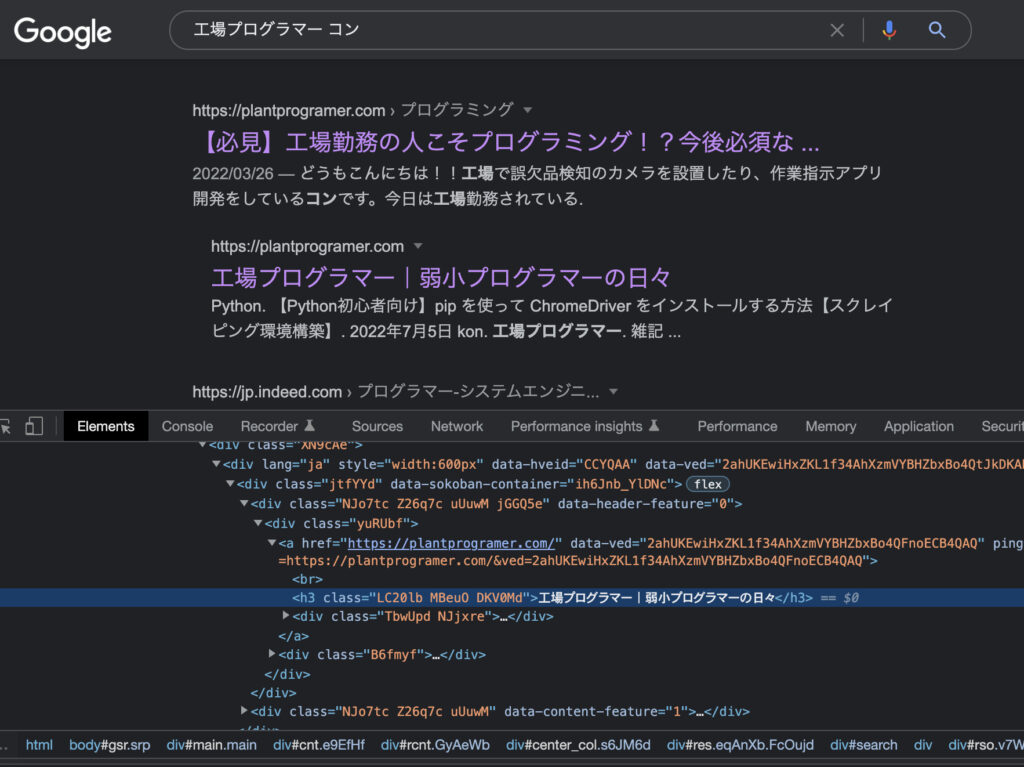
print(results)g.find_element_by_class_name(‘yuRUbf’).find_element_by_tag_name(‘a’).get_attribute(‘href’)
だったりのコードは
デベロッパーツールを使えば、理解できるようになってくると思います。
get_attribute()やtextの使い方は、まだ実は私も完璧ではなくて。。。
調べ調べでなんとか書けたな
というのが正直なところです( ; ; )
検索結果をCSVファイルに保存
最後にリストデータを保存します。
csv_data = ['title', 'url']
for row, result in enumerate(results):
temp_data = [result['title'], result['url']]
csv_data.append(temp_data)
np.savetxt("search_result.csv", csv_data, delimiter =",",fmt ='% s')
driver.close()
リスト化したデータはfor文とenumarate関数を使って保存していきます。
enumarate関数の使い方は以下のリンクから

コードまとめ
最後にコードをまとめておきます。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import chromedriver_binary
import time
from selenium.webdriver.common.by import By
import numpy as np
######seleniumを使うための設定######
INTERVAL = 3
URL = "https://www.google.com/"
driver = webdriver.Chrome()
driver.maximize_window()
time.sleep(INTERVAL)
driver.get(URL)
time.sleep(INTERVAL)
#検索したいワードを入力
search_word = '工場プログラマー コン'
#文字を入力して検索
driver.find_element('name', 'q').send_keys(search_word + Keys.ENTER)
#検索を実行
time.sleep(5)
#検索結果の一覧を取得する
results = []
flag = False
while True:
g_ary = driver.find_elements_by_class_name('g')
for g in g_ary:
result = {}
result['url'] = g.find_element_by_class_name('yuRUbf').find_element_by_tag_name('a').get_attribute('href')
result['title'] = g.find_element_by_tag_name('h3').text
results.append(result)
if len(results) >= 20: #抽出する件数を指定
flag = True
break
if flag:
break
driver.find_element_by_id('pnnext').click()
time.sleep(INTERVAL)
print(results)
csv_data = ['title', 'url']
for row, result in enumerate(results):
temp_data = [result['title'], result['url']]
csv_data.append(temp_data)
np.savetxt("search_result.csv", csv_data, delimiter =",",fmt ='% s')
driver.close()3. おわりに
ここまで読んでいただき、ありがとうございました。
実際に色々とスクレイピングに関するフリーランスの依頼はあったのですが。。。
特定のサイト内の検索だったりで、あまりサーバーへの負担をかけたくなかったので
Google検索で調べる方法を紹介させていただきました。
実際自分のブログをChromeの検索で調べたのは、今回が初めてだったのですが。。。
全然ヒットしませんね(笑)
アクセスログを時々見ているのですが、、、
1日に何人かアクセスしてくださっているんですが、一体どうやってこのブログを見つけてくださったのだろう。。。