本記事ではPythonのライブラリのpandasを使って、csvファイル中から特定の行のデータを抽出するコードを紹介します。
このコードだけでもpandasについて色々学べるため、是非読んでいってください。
今回使用するCSVとお題
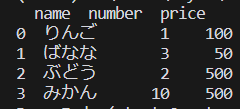
fruitdata.csvというname, number, priceのデータが入った下記の画像のようなデータを使用します。
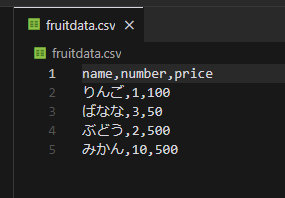
このCSVから以下の4パターンのデータを取得するコードを考えていきます。
nameが「ばなな」のデータが何行目か
Pythonコード
基本的には
(i) CSVファイルを読み込む
(ii) 条件を満たすロジックを書いていく
という順で実装していきます。
pandasのread_csvメソッドを使ってdf(データフレーム)というpndasの型に落とし込んで
そこからdfのname列からデータが「ばなな」になっているものを探します。
import pandas as pd
# CSVファイルを読み込む
df = pd.read_csv('fruitdata.csv')
# Trueのインデックスを取得
true_indices = df.index[df['name'] == 'ばなな'].tolist()
# 結果を出力=> print(true_indices)
print(true_indices)このコードの中にも
いくつか覚えて置いたほうがいい事があるので紹介していきます。
pd.read_csv
基本的にはCSVやエクセルファイルなんかは、pandasで読み込むのが良いです。
個人的な1番のポイントは今回のような日本語の情報が入ったファイルの取り扱いがしやすいからです。
numpyなどでcsvは読み込めますが、デフォルトでCSV読み込むと日本語入っているだけでエラー吐くのでpandasをオススメ。
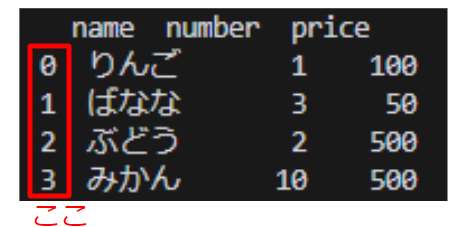
dfをprintで出力すると
のように左端にインデックスをつけてくれます。0から始まるところがPython仕様って感じがします。
df.index
df.indexはdfのインデックス部分を指します。dfを出力したの左端の列の数字です。
余談なのですがdf.indexをprintしてみると
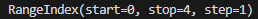
と表示されて[0, 1, 2, 3]ではない形で表現されます。
これはメモリ効率的に表現するための方法だそうです。数値が連続している場合に範囲とステップだけを記録することで、メモリ使用量を削減しています。
なので
df.index[条件].tolist()という形でdf.indexは条件を書いた後に、tolist()を書いてlist化しています。
おわりに
ここまで読んでいただき、誠にありがとうございました。
csvファイルの取り扱いは多くの職場で行うことなので、本記事が参考になれば幸いです。
javaScriptを書くようになっても、結局Pythonを使って何か処理はする今日この頃。
ライブラリもこの数年で色々出ていそうだから今度のGWに勉強してみたいです。
それでは。