どうもこんにちは。
工場では全くSNSの話題を出さないコンです。
みなさんは Word Cloud(ワードクラウド)ってご存知でしょうか??
これは文章や大量の語句の中から頻出語を頻度に比例する大きさで(多分)雲のように並べたものです。
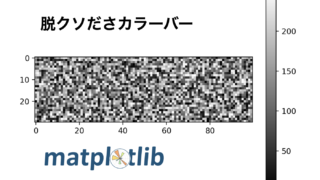
下記みたいなものが一例です。

このように頻出単語を可視化できるようになると
twitterのトレンドの把握が直感的にできるようになります。
今日はPythonを使ってTwitterのツイート情報を集めてwordcloudを作成していきます。
ライブラリーの準備
いくつかのライブラリを使用するので、先にpipでインストールしておきます。
今回は主に4つのライブラリです。
tweepy(ツイートの取得)
pip install tweepyMeCab(テキスト分析)
pip install mecab
pip install unidicWordCloud(ワードクラウドの作成)
pip install wordcloudこれでライブラリの準備は完了です。
特定のキーワードに関するワードクラウドを作成するコード
早速ですがコードを紹介いたします。
今回は本日たまたま日本のプロ野球で完全試合を達成した「佐々木郎希」選手に関するワードクラウドを作成しました。
import tweepy
from enum import IntEnum
import MeCab
import matplotlib.pyplot as plt
from wordcloud import WordCloud
class QUERY_KIND:
user = 0
keyword = 1
def get_tweet(keyword, query_kind):
"""
ツイートを取得する
keyword:検索するキーワード
query_kind:検索する種類()
"""
# TwitterAPIを記入する
consumer_key = 'hogehoge'
consumer_secret = 'hogehoge'
access_token_key = 'hogehoge'
access_token_secret = 'hogehoge'
#認証
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token_key, access_token_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
if query_kind == QUERY_KIND.user:
# userのツイートを取得する
tweets = api.user_timeline(count=1000, page=1)
elif query_kind == QUERY_KIND.keyword:
# 特定のキーワードのツイートを取得
tweets = api.search_tweets(q=keyword, count=1000,tweet_mode='extended')
else:
# エラー
tweets = []
return tweets
def tweets_analyze(tweets, file_name, background_color, color_type):
"""
ツイートの内容を分析する
tweets:取得したツイート
file_name:保存するファイル名
background_color:word cloudの背景色
color_type:word cloudの出力色
"""
#Mecabを使用して、形態素解析
mecab = MeCab.Tagger()
# 単語を入れる用
words = []
for tweet in tweets:
#tweetを分析
node = mecab.parseToNode(tweet)
# ツイート内容が終了するまで
while node:
word_type = node.feature.split(",")[0]
# "名詞", "動詞", "形容詞", "副詞"の中で選択したものを抽出
if word_type in ["名詞", "動詞", "形容詞", "副詞"]:
words.append(node.surface)
node = node.next
# テキストを連結
txts = " ".join(words)
#wordcloudで出力するフォントを指定(日本語を出力できるフォントを選択)
font_path = "/Library/Fonts//Arial Unicode.ttf"
# 特定のワードは入らないように設定
stop_words = ['佐々木', '朗希', '千葉', 'ロッテ', 'マリーンズ', 'https','RT','や', 'し'
'や', 'co', 't', '千葉ロッテマリーンズ', '朗', '希', 'ノーヒット', 'ノーヒットノーラン']
# WordCloudで出力
wordcloud = WordCloud(background_color=background_color,
colormap = color_type,
font_path=font_path,
stopwords=set(stop_words),
width=800,
height=600).generate(txts)
# 図を出力して保存
fig = plt.figure(figsize=(30, 10))
plt.imshow(wordcloud)
plt.axis("off")
plt.savefig(file_name,bbox_inches='tight')
plt.show()
if __name__ == "__main__":
# ツイートを取得
keyword = '佐々木朗希'
kind = QUERY_KIND.keyword
tweets_all = get_tweet(keyword, kind)
# ツイートを格納用
tweets = []
# リプを含めるかどうか
is_replay = True
# ツイート部分だけ格納
for tweet in tweets_all:
# リプを含めず分析するとき
if is_replay:
tweets.append(tweet.full_text)
else:
# @以外のツイートを取得
if '@' not in tweet.full_text:
tweets.append(tweet.full_text)
# ツイート分析
output_name = 'waste_investor.png'
background = 'white'
color_type = 'tab20'
tweets_analyze(tweets, output_name, background, color_type)出力結果
上のコードを実行した結果は以下のようになります。

やっぱり完全試合をした後なので、すごい感じのワードばかりです。
1試合19三振の記録であったり、キャッチャーの松川選手の名前もでております。
でも肝心な完全試合というワードはでてきてませんね。
これはおそらくMecabの辞書に完全試合が1つの単語として、登録されていないからかなと思っております。
Mecabを用いた形態素解析
Mecabってなんだよって話になってしまうかもしれませんが
これは形態素解析のためのオープンソースツールです。
形態素解析とは文章を意味のある最小の単位に分解して、意味や品詞など判別すること。です。
例えば
私はブロガーです⇨私(名詞)/は(助詞)/ブロガー(名詞)/です(助動詞)
みたいな。
これを使ってツイートの中身も名詞や動詞などに分類して、ワードクラウドで表現してます(^ ^)
とはいえ、今回は初期設定で行ったので、「いう」「よる」「こと」みたいな
あまり関係ないワードまで拾ってしまったので、精度はまだまだ向上させる工夫が必要だなって感じました。
おわりに
ワードクラウドができると、Twitterのトレンドを
いつもとは違った目線で分析できるため、非常に面白いですv(^_^v)♪
是非皆様も試してみてください。
ここまで読んでいただき、誠にありがとうございました!!