
・人の顔検出の手法を調べている方
・Pythonを使って人の顔検出を行おうとしている方
・簡単に実装できるコードを探している方
など
令和になってからも機械学習技術(ディープラーニング)の開発は爆速で進んでおり、
人の顔検出はより高速かつ正確に行うことができるようになっているようです。
私は2020年から工場で画像処理のプログラムを書いたりしているのですが
就職してからも色々な手法が編み出されており、最近置いてけぼりを食らってしまっております。。。
なので今こそ勉強の時!!(多分)
本記事では古典的な方法から最近の流行りの方法まで、色々な方法をPythonで実装しつつ
内容を解説していきたいと思います、
今回のお題の写真
今回は下のオーケストラ演奏中のお写真を使って、顔検出をやってみたいと思います。

まずは、私(人間)が人の顔をカウントするとこんな感じです。

22人の人の顔が写ってますね。
これらを検出できたかどうかを、いくつかの手法で評価して行きたいと思います。
Haar Cascades
Haar Cascadesは、Viola-Jones法と呼ばれる顔の特徴に基づいてトレーニングされた分類器を使用するアルゴリズムを使用します。
2001年の論文と、21世紀始まったばかりの時に出たアルゴリズムなのですが
今でも顔検出といえば〜に取り上げられる素晴らしいアルゴリズム。
https://www.slideshare.net/MPRG_Chubu_University/ss-32258845
アルゴリズムに関してはスライドシェアが非常に分かりやすいかったので共有いたします。
画像の一部分を切り出し、局所的な明暗差を算出して
この局所的な特徴をいくつも組み合わせることで、物体を判別できるようする手法らしい。
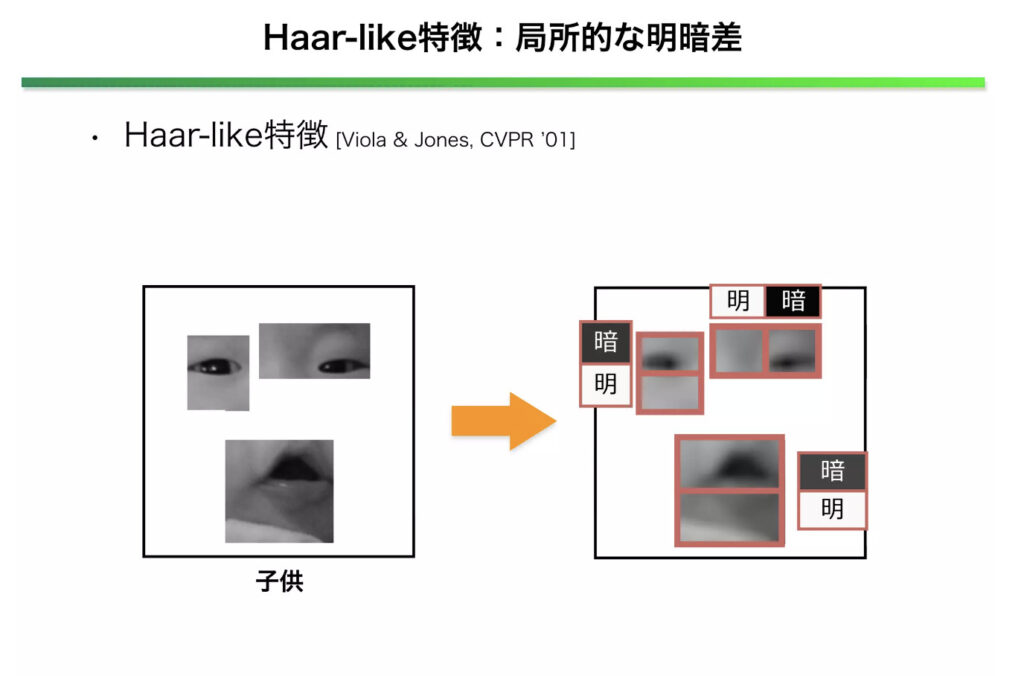
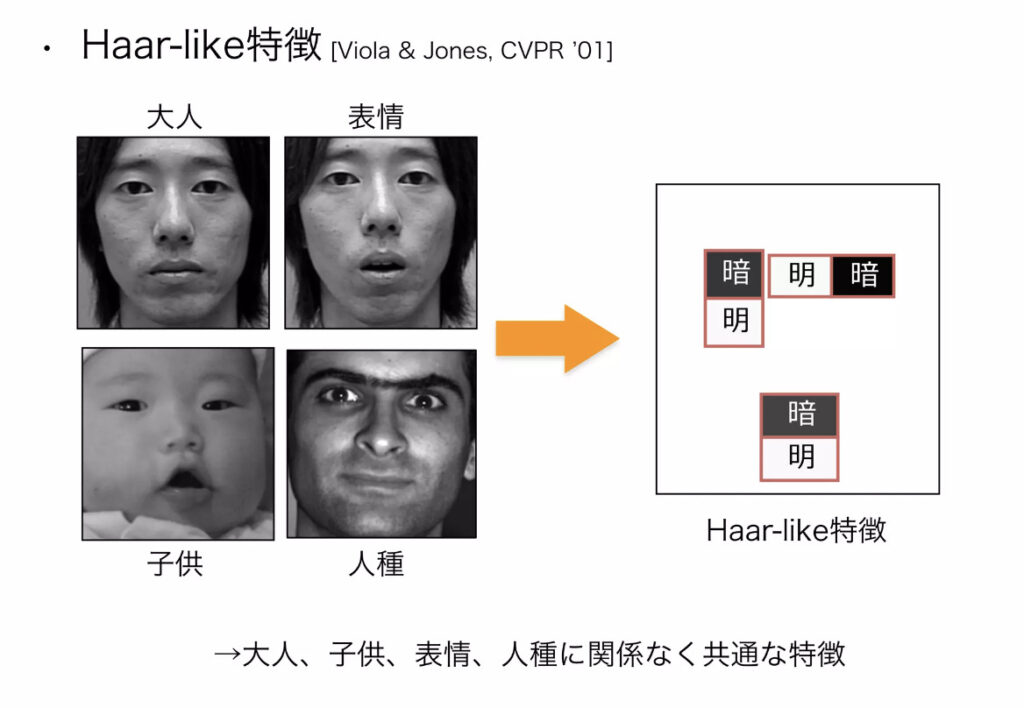
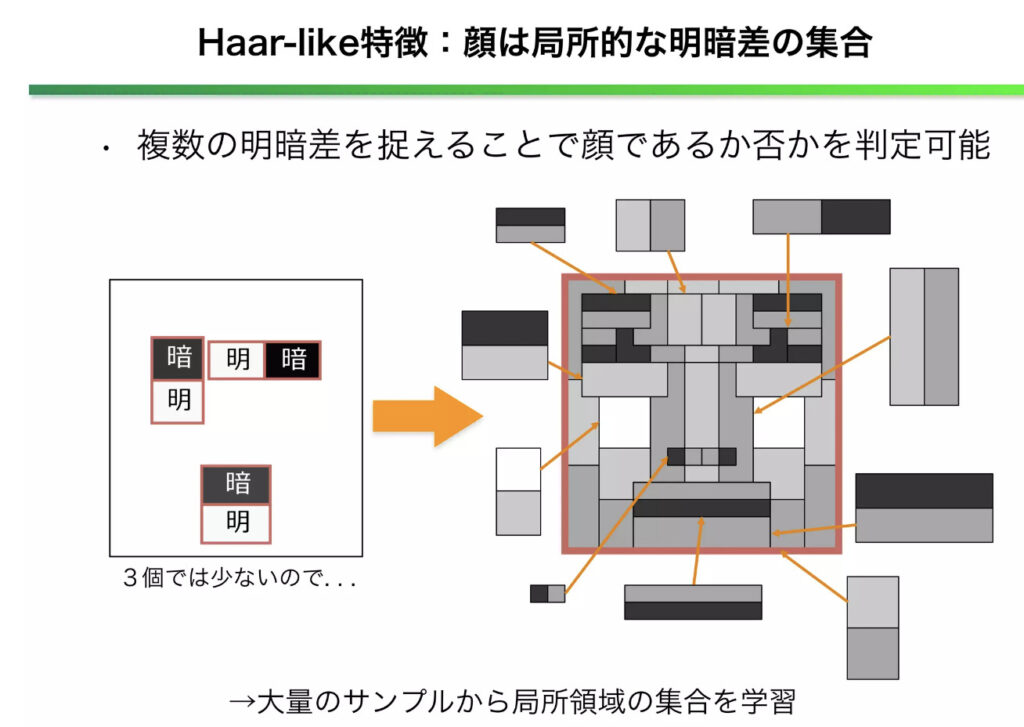
PythonではopenCVを使うと簡単に実装できます。
Haar Cascadesを使用して、静止画像内の人の顔を検出する方法を以下に示します。
import cv2
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
img = cv2.imread('many-faces-raw.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.1, 4)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
cv2.imwrite("haarcascade.jpeg", img)このコードは、静止画像内の人の顔を検出し、それらに青の枠を描画します。

11人検出することができました!
また2ヶ所ほど、誤検知になる結果にもなりましたね。。。
なんとなくですが、写真左側の斜めの顔は検出できないような結果になりました。
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)を使っているからかもしれませんが。。。
ミスしている箇所も、木目や服から暗い色と明るい色を含んだ部分を誤検出しており
アルゴリズム的にもそれらしい結果になったかと思います。
他の分類器を使うと違う結果かもしれない。
HOG特徴量+SVM分類
HOG(Histogram of Oriented Gradients)は、画像処理において、物体を検出するための特徴量の一つであり、人の顔検出にもよく使用されます。
2005年の論文のアルゴリズムで、Histgramと書いてあるように、グレイスケール画像における輝度の勾配を角度ごとにヒストグラム化したものであり,物体の形状を捉えるのに有効な特徴量です。
HOG 特徴量の取得には,まず入力画像をグレイスケール化し,各ピクセルの勾配方向と強度を算出するします。
その後,セル(5 × 5 ピクセル)ごとに輝度の勾配ヒストグラムを作成して,ブロック(2 ×2 セル) ごとに正規化する.これを順に連結したものを特徴量とする手法です。
下記の画像が分かりやすいと思います。
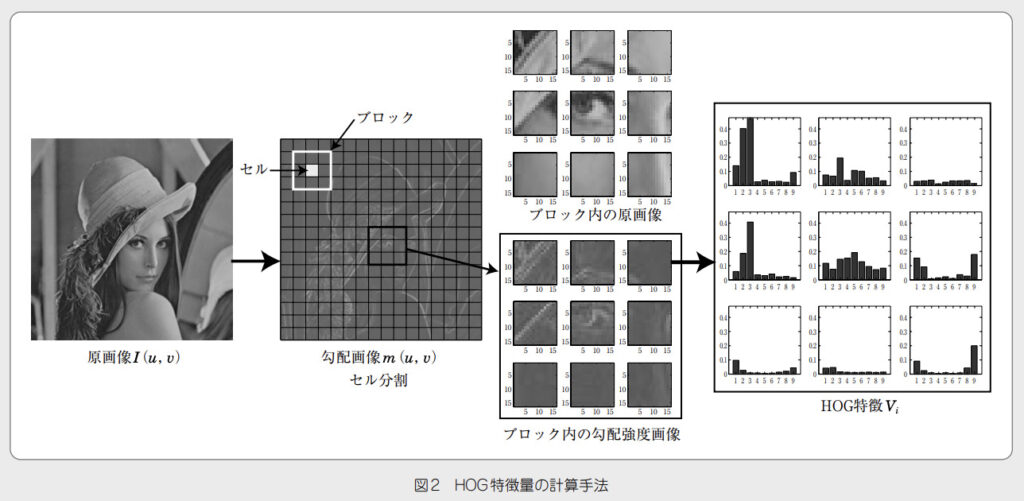
SVM(Support Vector Machine)は教師あり学習の手法の1つで、私も学生の時からお世話になっている手法の1つです。
顔を検出するアルゴリズム的には
1 分割した画像のHOG特徴量を計算する.
2 SVM(学習済み)を用いて分割した画像に人の顔が含まれているか予測する.
3 人の顔が含まれていれば, その画像のバウンディングボックス(分割したときの左上の座標と幅, 高さ)を保存する.
4. スライディングウィンドウ法で得られたバウンディングボックスのリストにNon-Maximum Suppressionを適用して重なっているバウンディングボックスを除外する.
を適用して、顔を検出する。
以下は、Pythonではdlibというライブラリを使って
HOG特徴量変換+SVMによるを使用して静止画像から人の顔を検出する方法を示すコードです。
import dlib
import cv2
detector = dlib.get_frontal_face_detector()
img = cv2.imread('many-faces-raw.jpeg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = detector(gray)
for face in faces:
x1 = face.left()
y1 = face.top()
x2 = face.right()
y2 = face.bottom()
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
cv2.imwrite("hog.jpeg", img)
このコードを実行して、オーケストラの画像から顔を検出した結果は以下のようになりました。

7件の人の顔を検出できていて、
ミスは0!!
検出力は少し下がりましたが、ミスしないようになりました。
MTCNN
MTCNN(Multi-task Cascaded Convolutional Networks)は、2016年に発表された、3つの畳み込みニューラルネットワークを組み合わせたアルゴリズムです。
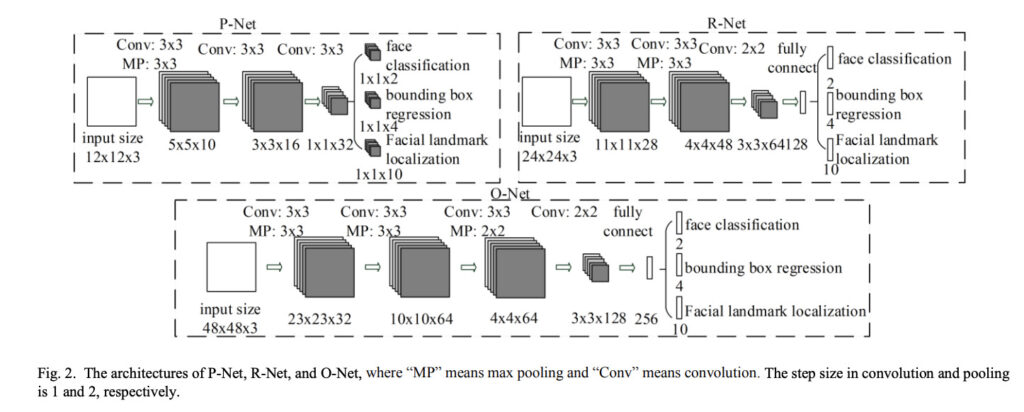
P-Net(Proposal Network)は、最初に全体的な顔の領域を検出するために使用されます。P-Netは、入力画像を畳み込み、各位置で複数の候補領域を生成します。
ここで生成された候補領域のサイズと位置に関する微調整をすることで、より正確な顔の候補領域を得ることを続いての層たちで行います。
R-Net(Refine Network)は、P-Netで検出された候補領域に対して、より正確な顔の検出を行います。
具体的には、R-Netは、P-Netで生成された候補領域を入力として、各候補領域に対して顔か非顔かの二値分類を行います。顔である場合は、顔の領域を微調整します。
O-Net(Output Network)は、最終的な顔の検出と顔のランドマーク検出を行います。
O-Netは、R-Netで生成された顔領域を入力として、顔か非顔かの二値分類と同時に、顔のランドマーク検出を行います。ランドマークとは、顔の輪郭、目、鼻、口などの部分の位置を表す点のことです。
これにより、検出された顔の領域がより正確なものに微調整され、同時にランドマークの位置も検出されるそう。
MTCNNは、静止画像や動画から人の顔を検出するためによく使用されます。
以下は、PythonでMTCNNを使用して静止画像から人の顔を検出する方法を示すコードです。
from mtcnn import MTCNN
import cv2
detector = MTCNN()
img = cv2.imread('many-faces-raw.jpeg')
result = detector.detect_faces(img)
for face in result:
x, y, width, height = face['box']
cv2.rectangle(img, (x, y), (x + width, y + height), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
cv2.imwrite("mtcnn.jpeg", img)
このコードを実行して、オーケストラの画像から顔を検出した結果は以下のようになりました。

13件の人の顔を検出できていて、
ミスは0!!
さすがディープラーニングを使った手法!!
かなり検出できるようになってきましたね。
画像の左側の顔が半分しか写っていない人も少しですが検出できるようになってきました。
時代はやはりDLなんだなぁ。。。
RetinaFace
RetinaFaceは、2019年に発表された顔検出アルゴリズムです。
このアルゴリズムは、MTCNNと同様に3つの異なるステージから構成されています。
最初のステージでは、P-Netと呼ばれる小型の畳み込みネットワークを使用して、候補領域を抽出します。
そして、R-Netと呼ばれる中程度の畳み込みネットワークを使用して、候補領域を正確にバウンディングボックスで囲みます。最後に、O-Netと呼ばれる大型の畳み込みネットワークを使用して、顔のランドマークを検出し、最終的なバウンディングボックスの位置を調整します。
(ここまではMTCNNと同じ)
MTCNNと異なるところについて、RetinaFaceは、非常に多様な環境下での顔検出に対応できるように、各ネットワークはピラミッド構造を使用して、複数の畳み込みネットワークを設計しています。
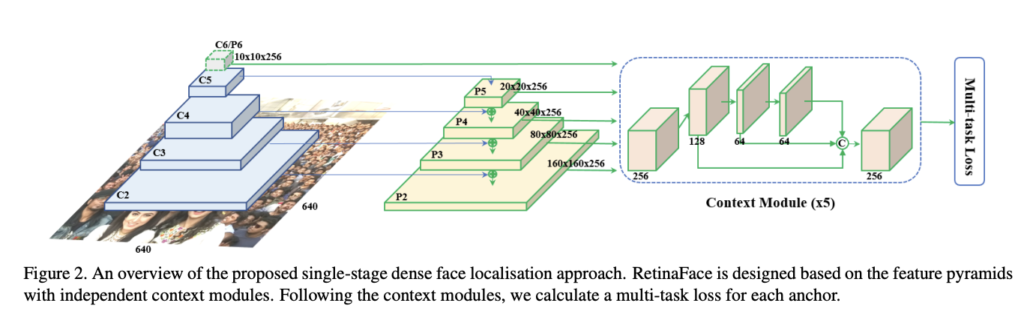
ピラミッド構造とは、入力画像を異なる解像度のサイズで複数作成し、それぞれの解像度で畳み込みニューラルネットワークを適用することで、異なるスケールで物体を検出する手法です。
つまりこのピラミッド構造を使用することで、正面だけでなく、様々な向きや角度、大きさの顔を検出することができるらしい。(正直論文読んでて分からなかった。。。)
from retinaface import RetinaFace
import cv2
img_path = 'many-faces-raw.jpeg'
img = cv2.imread(img_path)
resp = RetinaFace.detect_faces(img_path, threshold = 0.7)
print("faces:" + str(len(resp)))
def int_tuple(t):
return tuple(int(x) for x in t)
for key in resp:
identity = resp[key]
facial_area = identity["facial_area"]
cv2.rectangle(img, (facial_area , facial_area
, facial_area ), (facial_area[0], facial_area
), (facial_area[0], facial_area ), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
cv2.imwrite('retinaface.'+img_path.split("."), img)
), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey()
cv2.imwrite('retinaface.'+img_path.split("."), img)
このコードを実行して、オーケストラの画像から顔を検出した結果は以下のようになりました。

22件の全員人の顔を検出できていて、
ミスは0!!
人類は最強の顔検出を生み出してしまったのだ。。。
今回はこの画像だけだったので、たまたまだったかもしれませんが
おそらく仕事で使うのだったら、RetinaFaceをさっさと使うかもしれません。
おわりに
今回の結果をまとめると以下の結果になりました。
| お題の画像 | Haar Cascades | HOG特徴量+SVM分類 | MTCNN | RetinaFace | |
| 顔の数 | 22 | 11 | 7 | 13 | 22 |
| ミス | – | 2 | 0 | 0 | 0 |
やはり新しい手法になるにつれて、精度がどんどん良くなっていますね。
人類の進歩?を感じます。
実は、この記事を書いている時にピラミッド構造を知りました。
ずっと工場で働いていると、既存の手法を使い回すことが多くて、AIの知識のアップデートもあまり出来ずにいるのがデメリットですね(笑)
基本情報の勉強も終わりましたし、また色々な手法を調べて記事にしたいと思います。













工場でpythonで画像処理して…ということをされてるんですね。私がしたいことを既にされてるということで非常に参考になります!
コメントありがとうございます!!
書いていただいた通り、カメラとパソコン使った画像系の仕事をしてます📷
雑記で色々書くブログですが
何かしら読んでいただいた人の参考になれば
私も嬉しいです。
重ね重ねではありますが、コメントありがとございます!!